Lessons from building AI Features
I'm not sure if these are deeply profound or bleedingly obvious

I recently built a feature that uses an LLM to do some data / workflow validation. Here are some things I learned. I like writing about this because I think there’s a huge discrepancy in industry capability here. Some people will find my notes really trivial, while others will (I hope) learn something new and eye opening.
The feature I built is pretty in the weeds of our product and I don’t want to give away all the secrets so this will be a bit vague at parts. Hopefully it’s useful anyway.
1. Take inspiration from AI coding
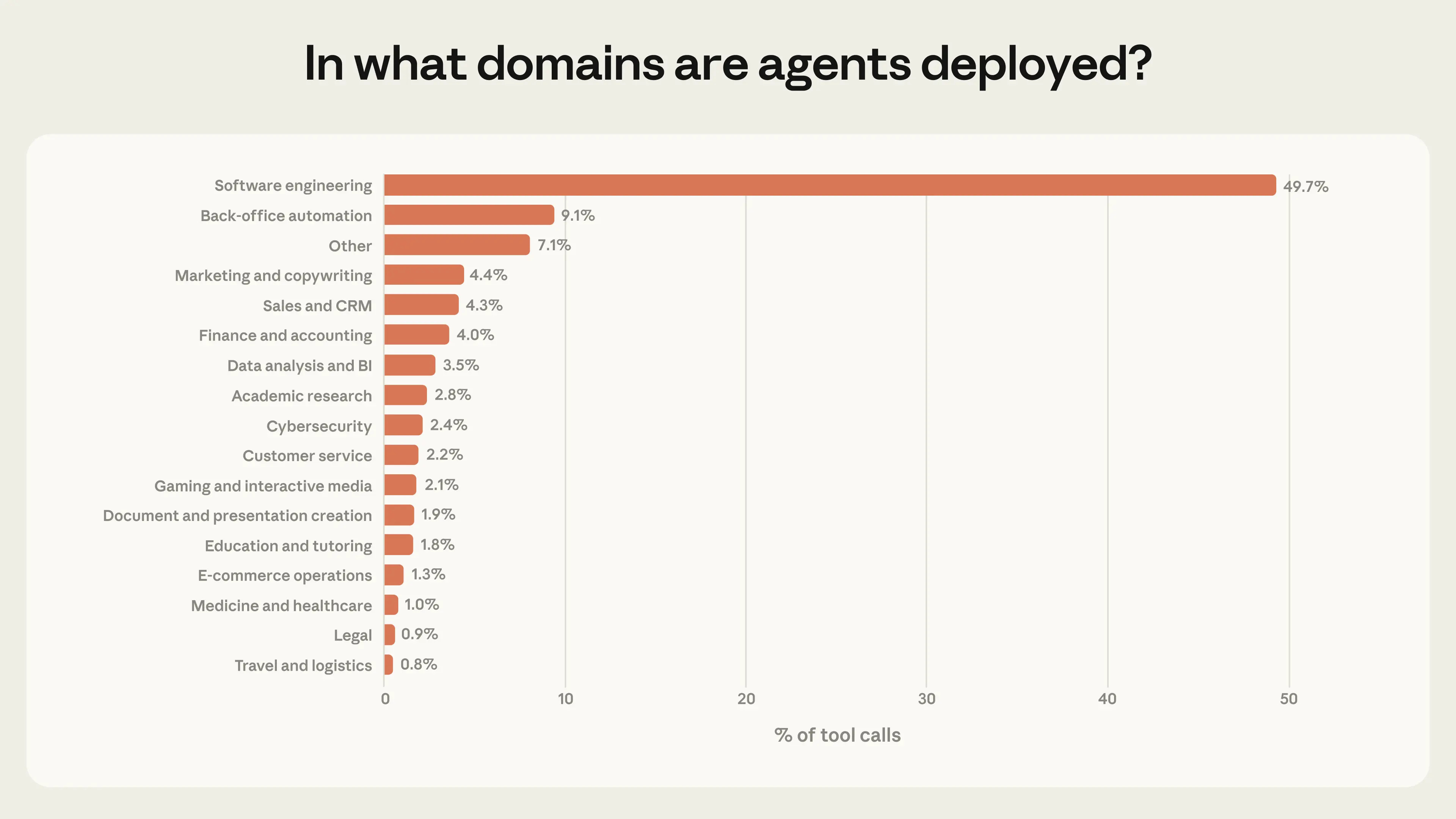
Coding is far and away the main use case for AI agents. So it’s where you’ll find the most refined patterns and the best new ideas. For example, CLAUDE.md is easy to explain:
Claude Code writes code that’s wrong
You explain the mistake in CLAUDE.md
It’ll never make that mistake again
You can apply this concept to other things too! The feature I built is for validating that a user has done some task correctly based on customer-specific business rules. In the past that may have required writing a complex rules engine or doing extensive user training. Now, we give the customer a text box to write down their rules - just like a CLAUDE.md.
There’s lots of other patterns being developed in the AI coding world that’ll translate well to other domains if you know the domain well enough. “Agents” is an obvious (if vague) one but if you think a bit deeper you’ll find much ones.
2. Strip away the LLM
The first version of my feature was all LLM driven. Users would type in their business rules, then we’d send all those rules + the relevant task data to an LLM and ask it to validate things.
This was very slow and the results weren’t the same every time. That’s not a surprise - LLMs are slow and probabilistic. If you’re using them for stuff where you need a fast and deterministic answer, you’re using the wrong tool.
Eventually I narrowed the LLM scope to just parsing the user’s input and turning it into a structured set of rules that code could parse and evaluate, in a fast and deterministic way.
In some cases you’ll be able to strip the LLM away until everything is just code. That’s a good thing! LLMs are great for prototyping, but if it turns out your “AI feature” will work without AI, that’s not a bad thing.
3. Build a test harness
Everyone talks about evals. What does that mean?
A simple answer I landed on is a unit test that calls my code that calls the Anthropic API. By writing it like any other unit test I get all the benefits of using my existing testing framework. I just made it not run in CI, and require an API key to be passed in when running it.
I chose to not run it in CI because the test is pretty flakey compared to a normal test. It’s also not free. While developing I can re run it often. This gives me much more confidence in changing the prompt it tests, as well as all the code around it. Otherwise I’d be totally flying blind, or spending huge amounts of time manually QAing.
4. Make it easy for users to debug
Read this post for some good examples of what this means:

Making the feature easy for users to debug makes my life easier when I’m building and testing and it’ll make everyone’s life easier as we deploy the feature more widely. This requires my thought in an AI world because while users may claim to want magic, they also want to know the exact process by which the magical answer was derived.
There’s other lessons that were (even more!) domain specific, but these four feel worth keeping in mind for future projects.